Termes, expressions, et algorithmes
Cette section contient une description des termes habituels et des expressions utilisés dans WinSplits Pro, dans l'ordre alphabétique. Les algorithmes utilisés pour calculer diverses mesures sont également expliqués dans ce chapitre.
WinSplits Pro permet de créer vos propres parcours contenant uniquement certains coureurs ou tronçons. De tels parcours sont appelés catégories spéciales, et celles-ci vous permettent de comparer des coureurs en dehors des limites de leur catégorie, ou uniquement sur une certaine partie du parcours original.
Le coureur de référence affecte plusieurs fonctions différentes dans WinSplits Pro.
- Lorsque le parcours est composé de boucles que les coureurs parcourent dans un ordre différent (relais homme-seul), ou si le procédé "papillon" est utilisé, les temps intermédiaires sont triés dans le même ordre que celui effectué par le coureur de référence.
- Dans certaines tables et graphiques, des temps et des différences de temps peuvent être affichés par rapport à ce coureur de référence.
- La numérotation des contrôles des catégories spéciales suit celle du coureur de référence sélectionné.
WinSplits Pro sauvegarde les données de temps intermédiaires avec l'extension .spl. Chaque fichier contient l'information d'un événement.
La fréquence d'erreur d'un coureur est calculée en divisant le nombre de ses tronçons avec erreur par le nombre total de tronçons de ce parcours.
L'indice de lièvre évalue combien un coureur a été suivi par d'autres, ou en tête d'un groupe. L'indice de suiveur indique combien un coureur en a suivi d'autres, ou encore combien de temps il a passé en seconde (ou encore plus mauvaise position) dans un groupe. Ensemble, ces indices de lièvre et de suiveur sont dénommés indice de regroupement, et peuvent être affichés pour un tronçon individuel ou sur la totalité du parcours. L'indice de regroupement pour l'entièreté d'un parcours est la somme de chaque indice de tronçon, pondérée par la longueur du tronçon.
Le calcul des indices de lièvre et de suiveur est basé sur une interpolation linéaire des heures de passage aux postes de contrôles. A chaque instant au cours du tronçon, l'indice de lièvre est recalculé selon la règle ci-dessous. L'indice de suiveur est calculé de la même manière. (intervertir respectivement les termes "devant" et "derrière", "lièvre" et "suiveur" dans l'explication ci-dessous.
- Un coureur est de 0 à 7 secondes devant un autre: 100% indice de lièvre.
- Un coureur est de 7 à 20 secondes devant un autre: pente linéaire de 100% à to 0% (13,5 secondes devant constituent un indice de lièvre de 50%).
- Un coureur est plus de 20 secondes devant un autre: indice de lièvre: 0%.
L'indice de lièvre du tronçon est alors obtenu en l'intégrant sur la longueur du tronçon. Si deux coureurs sont séparés par plus de 20 secondes à un contrôle, on considère qu'il n'y a pas de suiveur sur ce tronçon. Deux coureurs qui poinçonnent au même moment reçoivent un indice de lièvre de 50%.
Exemple: le coureur A (ligne noire du diagramme) poinçonne 11 secondes après le coureur B(bleu) à un contrôle, mais poinçonne 5 secondes avant lui au contrôle suivant.
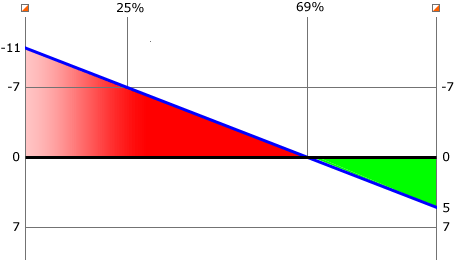
L'interpolation linéaire considère que A a dépassé B là où les lignes se croisent après 69 % du tronçon. Pour le reste du tronçon, A a un indice de lièvre de 100%. Dès lors, l'indice de lièvre de A sur l'ensemble du tronçon est de (1-0.69)*100% = 31%.
L'indice de lièvre de B entre 0 et 25% du tronçon (lorsque la différence de temps entre les coureurs est de 7 secondes) passe de (1-(11-7)/(20-7))*100% = 69% à 100%. L'indice de lièvre moyen de B sur cette partie du tronçon est donc (69+100)/2 = 34,5%. L'indice de lièvre de B entre 25 et 69% du tronçon est de 100%. Sur la fin du tronçon, B court derrière A, et son indice de lièvre est donc 0%. Dès lors l'indice de lièvre de B pour l'ensemble du tronçon est 0.25*34.5+0.44*100+0.31*0 = 53%.
Si le coureur A enmène un groupe serré, suivi par B et C, l'indice de lièvre de B est à 0%, puisque B, à son tour suit A, qui fait le travail dans ce groupe. La somme des indices de lièvre et de suiveur sur un tronçon donné ne peut jamais dépasser 100%.
Ces indices de lièvre et de suiveur sont des mesures à interpréter soigneusement, spécialement au niveau du tronçon, car on ignore ce qui se passe exactement pour un groupe durant un tronçon. Les seules données utilisées pour cette évaluation sont les heures de passage, uniquement disponibles au contrôle. Sur l'ensemble d'un parcours, les variations de groupes qui peuvent se produire sur des tronçons individuels sont normallement équilibrées, signifiant que ces indices deviennent alors des mesures plus fiables.
L'indice de performance est une mesure de la performance d'un coureur par rapport aux coureurs les plus rapides de la catégorie. Pour chaque tronçon, un quotient de la moyenne du quart (25%) des meilleurs temps intermédiaires par le temps intermédaire du coureur est calculé. Ces quotients sont appelés indices de performance. Utiliser la moyenne des 25% des meilleurs temps donne une mesure plus ferme.
Un indice de performance de 100% siginifie, par définition, que le temps intermédiaire du coureur est le même que la moyenne des 25 % meilleurs temps sur ce tronçon. Plus élevé est cet indice, meilleure est la performance. L'indice de performance pour l'ensemble du parcours est calculé comme étant le quotient de la somme des moyennes des 25% meilleurs temps intermédiaires sur chaque tronçon par le résultat final du coureur.
Analyser une liste triée sur les indices de performance de tronçon d'un coureur peut fournir quelques d'informations. Un telle liste peut clairement montrer quel types de tronçons ont présenté les plus grandes difficultés pour le coureur, et quels types lui ont le mieux convenu.
WinSplits Pro peut estimer la perte de temps d'un coureur due à des erreur en analysant les temps intermédiaires de ce coureur. Pour chaque tronçon, le quotient de la moyenne du quart (25%) des meilleurs temps intermédiaires par le temps intermédiaire du coureur est calculé. Ces quotients sont appelés indices de performance. La valeur médiane des indices de performance du coureur sur l'ensemble du parcours, pondérés par la longueur des tronçons, est considérée comme la performance normale du coureur pour le parcours.
Pour chaque tronçon, la différence (à la fois en temps et en pourcent) entre le temps intermédiaire réel et celui que le coureur devrait avoir avec sa performance normale est calculée. Les tronçons pour lesquels cette différence est supérieure aux deux seuils d'erreur sont considérés comme tronçons avec erreur, et les temps perdus sur ces tronçons sont fixés à ces différences.
Cette approche de la perte de temps devient plus fiable pour des catégories plus importantes en nombre de coureurs, et plus homogènes, c.à.d. avec des coureurs de capacité similaire.
Le concept de régularité peut avoir différentes significations qui dépendent de leur contexte d'utilisation. Mais dans tous les cas, une valeur plus faible indique une meilleure régularité.
- Pour une catégorie: la déviation standard moyenne des indices de performance des coureurs sur l'ensemble du parcours.
- Pour un coureur: la déviation standard des indices de performances du coureur par tronçon, pondérée par la longueur du tronçon.
- Pour un tronçon: la déviation standard de l'indice de performance de tous les coureurs sur ce tronçon.
Le seuil d'erreur indique la différence minimale entre le temps intermédiaire d'un coureur et le temps qu'il devrait avoir avec une performance normale sur un tronçon. Ce seuil est suffisant pour que WinSplits détermine si le coureur a commis une erreur sur ce tronçon. Autrement dit, un tronçon est considéré comme comportant une erreur si la différence est supérieure au seuil d'erreur. Le seuil d'erreur consiste en une double valeur, en temps et en poucent et les deux doivent être dépassées pour que WinSplits considère qu'une erreur a été commise. Le seuil d'erreur peut être ajusté de telle manière qu'il corresponde au mieux au niveau des coureurs, au type d'événement et au terrain.
En utilisant l'indice de suiveur comme base, WinSplits Pro peut calculer combien de temps un coureur a gagné en en suivant d'autres, à la fois sur chaque tronçon et sur l'ensemble de la course. Cette évaluation doit être considérée comme assez basique et dès lors interprétée avec précaution.
L'algorithme évalue tout d'abord l'indice de performance moyen du coureur pour les tronçons où il n'y a pas eu de "suivi". Cet indice de performance sans suivi est alors appliqué aux parties de la course où le coureur en a suivi d'autres, et une différence de temps entre le temps réel et le temps sans suivi est alors obtenue pour chaque tronçon. Ces différences peuvent être positives et négatives. Une différence négative indique que le coureur a effectivement perdu du temps en suivant.
Le temps idéal (ou temps de Superman) pour une catégorie est la somme des meilleurs temps intermédiaires de chaque tronçon.
Un temps intermédiaire est le temps mis d'un contrôle au suivant.
Un temps total est le temps depuis le départ jusque et y compris un contrôle défini.
Une heure de passage est l'heure de la journée à laquelle un coureur a poinçonné à un contrôle défini.
Le temps sans erreur d'un coureur est le temps restant lorsque sa perte de temps totale sur le parcours a été déduite de son résultat.
Les vues analytiques (ou modes) sont les options qui déterminent les contenus et apparences des diverses listes de résultats, tables, et replay dans WinSplits Pro. Vous pouvez sélectionner les vues désirées à gauche de la barre d'outils. Des vues supplémentaires peuvent être téléchargées depuis la page d'accueil de WinSplits.